Tarjan 算法求强连通分量
最近公共祖先 - OI Wiki
(塔杨算法)
Robert E. Tarjan(罗伯特·塔扬,1948~),生于美国加州波莫纳,计算机科学家。
Tarjan 发明了很多算法和数据结构。不少他发明的算法都以他的名字命名,以至于有时会让人混淆几种不同的算法。比如
- 求各种连通分量的 Tarjan 算法,
- 求 LCA(Lowest Common Ancestor,最近公共祖先)的 Tarjan 算法。
- 并查集、Splay、Toptree 也是 Tarjan 发明的。
连通分量的 Tarjan 算法
DFS 生成树

返祖边 横叉边 前向边
- 返祖边与树边必构成环
- 横叉边可能与树边构成环
- 前向边无用
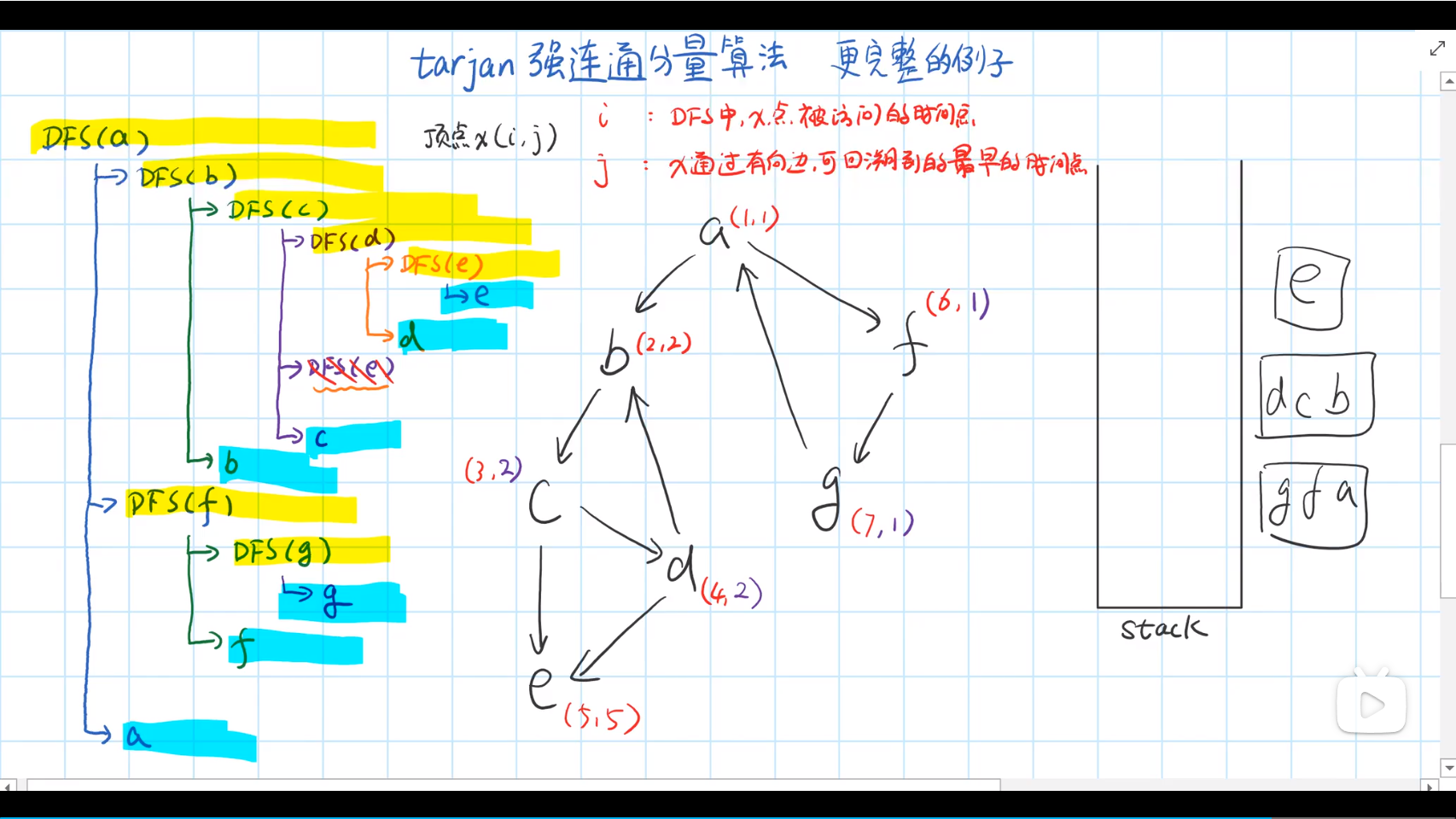
Tarjan 算法求强连通分量
强连通分量 SCC(strongly connected component)
在 Tarjan 算法中为每个结点
一个结点的子树内结点的 dfn 都大于该结点的 dfn。
从根开始的一条路径上的 dfn 严格递增,low 严格非降。
按照深度优先搜索算法搜索的次序对图中所有的结点进行搜索,维护每个结点的 dfn 与 low 变量,且让搜索到的结点入栈。每当找到一个强连通元素,就按照该元素包含结点数目让栈中元素出栈。在搜索过程中,对于结点
- v 未被访问:继续对 v 进行深度搜索。在回溯过程中,用
更新 。因为存在从 到 的直接路径,所以 能够回溯到的已经在栈中的结点, 也一定能够回溯到。 - v 被访问过,已经在栈中:根据 low 值的定义,用 \textit{dfn}_v 更新 \textit{low}_u。
- v 被访问过,已不在栈中:说明 v 已搜索完毕,其所在连通分量已被处理,所以不用对其做操作。
将上述算法写成伪代码:
TARJAN_SEARCH(int u)
vis[u]=true
low[u]=dfn[u]=++dfncnt
push u to the stack
for each (u,v) then do
if v hasn't been searched then
TARJAN_SEARCH(v) // 搜索
low[u]=min(low[u],low[v]) // 回溯
else if v has been in the stack then
low[u]=min(low[u],low[v])//low[v]<->dfn[v]
对于一个连通分量图,我们很容易想到,在该连通图中有且仅有一个 u 使得
因此,在回溯的过程中,判定
实现
oi.wiki 模板
int dfn[N], low[N], dfncnt, s[N], in_stack[N], tp;
int scc[N], sc; // 结点 i 所在 SCC 的编号
int sz[N]; // 强连通 i 的大小
void tarjan(int u) {
low[u] = dfn[u] = ++dfncnt, s[++tp] = u, in_stack[u] = 1;
for (int i = h[u]; i; i = e[i].nex) {//链式前向星的存图方式
const int &v = e[i].t;
if (!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
} else if (in_stack[v]) {
low[u] = min(low[u], low[v]);
}
}
if (dfn[u] == low[u]) {
++sc;
while (s[tp] != u) {
scc[s[tp]] = sc;
sz[sc]++;
in_stack[s[tp]] = 0;
--tp;
}
scc[s[tp]] = sc;
sz[sc]++;
in_stack[s[tp]] = 0;
--tp;
}
}
董晓算法模板:
vector<int> e[N];
int dfn[N], low[N],instk[N],siz[N],scc[N],stk[N],top,tot,cnt;
void tarjan(int x) {
dfn[x] = low[x] = ++tot;
stk[++top] = x;
instk[x] = 1;
for (int y : e[x]) {
if (!dfn[y]) {
tarjan(y);
low[x] = min(low[x], low[y]);
} else if (instk[y]) {
low[x] = min(low[x], low[y]);
}
}
if (dfn[x] == low[x]) {
int y;
++cnt;
do {
y = stk[top--];
instk[y] = 0;
scc[y] = cnt;
++siz[cnt];
} while (y != x);
}
}
//多组数据清空
memset(dfn, 0, sizeof dfn);
memset(low, 0, sizeof low);
memset(scc, 0, sizeof scc);
memset(siz, 0, sizeof siz);
memset(instk, 0, sizeof instk);
memset(stk, 0, sizeof stk);
memset(in, 0, sizeof in);
memset(out, 0, sizeof out);
for (int i = 1; i <= n; i++)
e[i].clear();
cnt = 0, tot = 0, top = 0;
//计算入度出度
for (int i = 1; i <= n;i++)
{
for(auto v:e[i])
{
if(scc[i]!=scc[v])
{
out[scc[i]]++;
in[scc[v]]++;
}
}
}
//董晓模板各个变量的作用
1. vector<int> e[N]: 存储了图中每个节点的邻接节点列表。
2. int dfn[N]: 用于记录每个节点被遍历到的时间戳(深度优先搜索的遍历顺序)。
3. int low[N]: 用于记录每个节点能够回溯到的最早的时间戳。
4. int instk[N]: 用于记录每个节点是否在栈中。
5. int siz[N]: 用于记录每个强连通分量的大小。
6. int scc[N]: 用于记录每个节点所属的强连通分量编号。
7. int stk[N]: 用于模拟栈的操作,在tarjan算法中用于存储遍历过的节点。
8. int top: 用于记录栈顶的位置。
9. int tot: 用于记录当前遍历的时间戳。
10. int cnt: 用于记录强连通分量的个数。
练习
- LibreOJ ../../ACMExercises/z-Misc/受欢迎的牛 P 2341 [USACO 03 FALL / HAOI 2006] 受欢迎的牛 G - 洛谷(一样的题)
- Site Unreachable ../../ACMExercises/z-Misc/Network of Schools P 2746 [USACO 5.3] 校园网 Network of Schools - 洛谷
P 2812 校园网络【[USACO]Network of Schools 加强版】 - 洛谷(三个题是一样的) - P 2863 [USACO 06 JAN] The Cow Prom S - 洛谷(模板) ../../ACMExercises/Luogu/P2863 The Cow Prom S - 洛谷
- ../../ACMExercises/z-Misc/Proving Equivalences
- ../../ACMExercises/z-Misc/The Largest Clique
tarjan 算法求 lca 见 lca